
Paper link | Code link | EMNLP 2023
這項新任務是透過一種定義了兩階段訓練過程(監督學習和強化學習)的方法來生成不同風格的問題。
這種方法確保了生成的問題既具有一致性又具備多樣性。
近期的研究主要集中在給定的段落或語義詞空間,以進行多樣化的內容規劃。
然而,外部知識在增強表達多樣性方面的潛力仍需更多的考量。
本研究針對檢索增強風格轉換(RAST),旨在利用外部知識生成使用多樣模板的問題,以提升表達的多樣性。
問題生成(Question Generation, QG)是一項根據給定答案和基礎段落生成問題的任務。

然而,QG 系統面臨兩個主要問題:
RAST(檢索增強風格轉換)是一個框架,通過從外部集合中檢索問題風格模板,並利用這些模板來生成具有多樣表達的問題。
它包含三個主要組件:
RAST中的風格檢索器和基於風格的生成器可以通過基於強化學習(RL)的方法聯合訓練。
這種RL方法直接最大化一致性和多樣性獎勵的平衡組合,有效解決了不一致性和缺乏多樣性的問題。
在問題生成(Question Generation, QG)中,給定一段文字  和答案
和答案 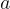 ,需要生成問題
,需要生成問題 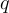 。
。
在這裡,我們可以將 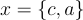 視為輸入。
視為輸入。
以往的研究針對 QG 任務建模 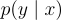 如下:
如下:
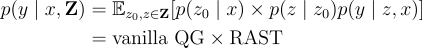
其中,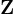 是問題風格模板的外部資料庫,
是問題風格模板的外部資料庫,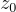 是根據上下文
是根據上下文 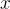 可以預測的初始問題模板。
可以預測的初始問題模板。

系統會從外部知識中選擇與初始模板  相似但不完全相同的風格模板
相似但不完全相同的風格模板 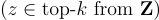 。這些風格模板隨後用於生成問題。
。這些風格模板隨後用於生成問題。
在訓練過程中,給定上下文 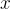 時,初始模板 是通過屏蔽上下文相關資訊,從真實問題
時,初始模板 是通過屏蔽上下文相關資訊,從真實問題 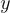 中提取出來的。
中提取出來的。
在推理過程中,系統使用基礎問題生成模型 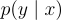 來生成最佳候選問題
來生成最佳候選問題 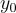 ,然後從中提取出初始模板
,然後從中提取出初始模板 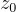 。
。
Masking
問題模板是通過屏蔽上下文相關資訊從收集到的問題中獲得的。
Duplication removal
通過測量成對的 Jaccard 相似度來移除近似重複的模板。
Style Retrieval Model
查詢和樣本風格的編碼方式如下:
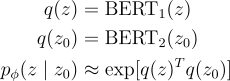
其中,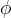 是兩個 encoder 的參數。
是兩個 encoder 的參數。
Style Transfer Model
他們使用 T5 作為風格轉換模型:
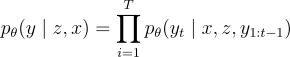
其中,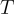 表示問題的長度,
表示問題的長度,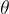 是模型參數。
是模型參數。
監督學習(Supervised Learning): 用於初始化風格轉換模型。
強化學習(Reinforcement Learning, RL): 應用於避免暴露偏差,並解決訓練和測試之間的評估差異。
由於在 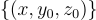 上的原始訓練過程可能會遭遇過擬合,他們引入噪音到模板
上的原始訓練過程可能會遭遇過擬合,他們引入噪音到模板 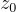 以建立一個噪音模板
以建立一個噪音模板 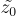 :
:
然後,他們使用 cross entropy loss 來訓練模型:
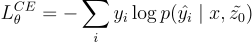
其中,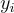 代表預設答案標籤,
代表預設答案標籤,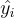 代表在時間步
代表在時間步  的預測標籤。
的預測標籤。
RL for Style Retrieval and Transfer
在 RAST 中,系統被視為一個與由單詞和問題模板組成的外部環境互動的代理。綜合策略涉及選擇風格或預測下一個單詞。目標是最小化的獎勳函數給出如下:
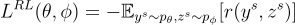
其中,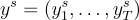 代表從風格轉換模型
代表從風格轉換模型 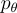 中抽樣的單詞,
中抽樣的單詞,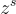 表示從風格檢索模型
表示從風格檢索模型 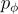 中抽樣的模板。
中抽樣的模板。
Reward Model
Consistency Reward
為了解決第一個問題,不一致性獎勳受到一篇關於問題回答的論文啟發。他們使用基於 T5 的生成性 QA 模型。不一致性獎勳的測量方法如下:
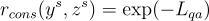
其中
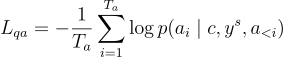
在這裡,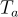 是答案的長度,
是答案的長度,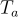 是從
是從 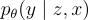 中抽樣的問題。
中抽樣的問題。
Diversity Reward
為了解決第二個問題,多樣性獎勳使用 Jaccard 相似度,其定義為:
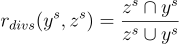
最終的總獎勳計算如下:
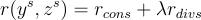
其中,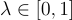 是平衡參數。
是平衡參數。

在這項研究中,使用了兩個公共數據集:
評估中使用了以下指標:
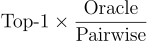 。
。注意,所有報告的 BLEU 分數均為 BLEU-4。
下圖顯示了在 NewsQA 和兩個 SQuAD 切分上不同技術的比較:

以下是三個 RAST 輸出示例,每個示例展示了不同類型的問題。在每個示例中,給定的答案在源上下文中用紅色突出顯示:


 iThome鐵人賽
iThome鐵人賽